
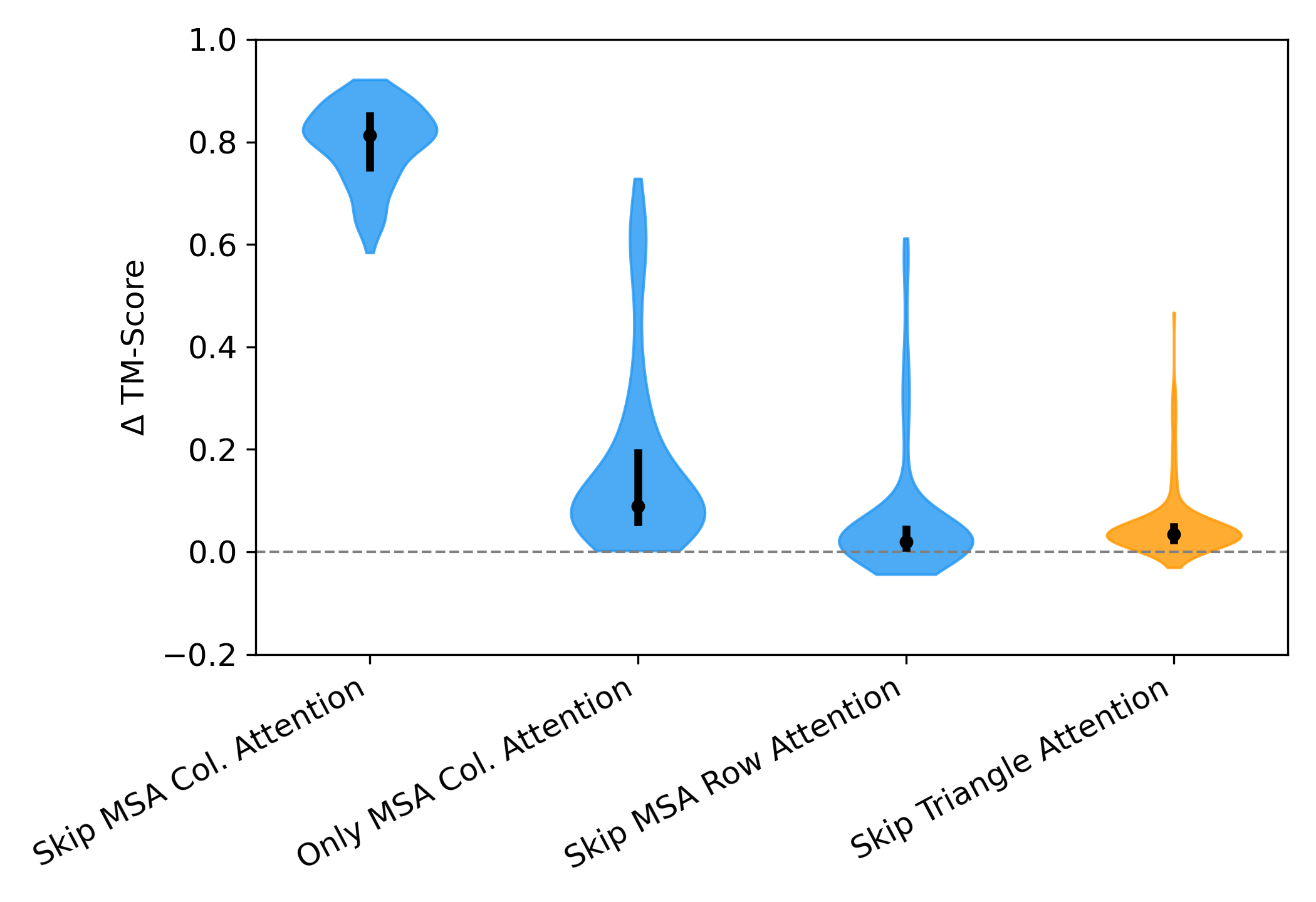
Models such as AlphaFold2 and OpenFold have transformed protein structure prediction, yet their inner workings remain poorly understood. We present a methodology to systematically evaluate the contribution of individual OpenFold components to structure prediction accuracy. We identify several components that are critical for most proteins, while others vary in importance across proteins. We further show that the contribution of several components is correlated with protein length. These findings provide insight into how OpenFold achieves accurate predictions and highlight directions for interpreting protein prediction networks more broadly.
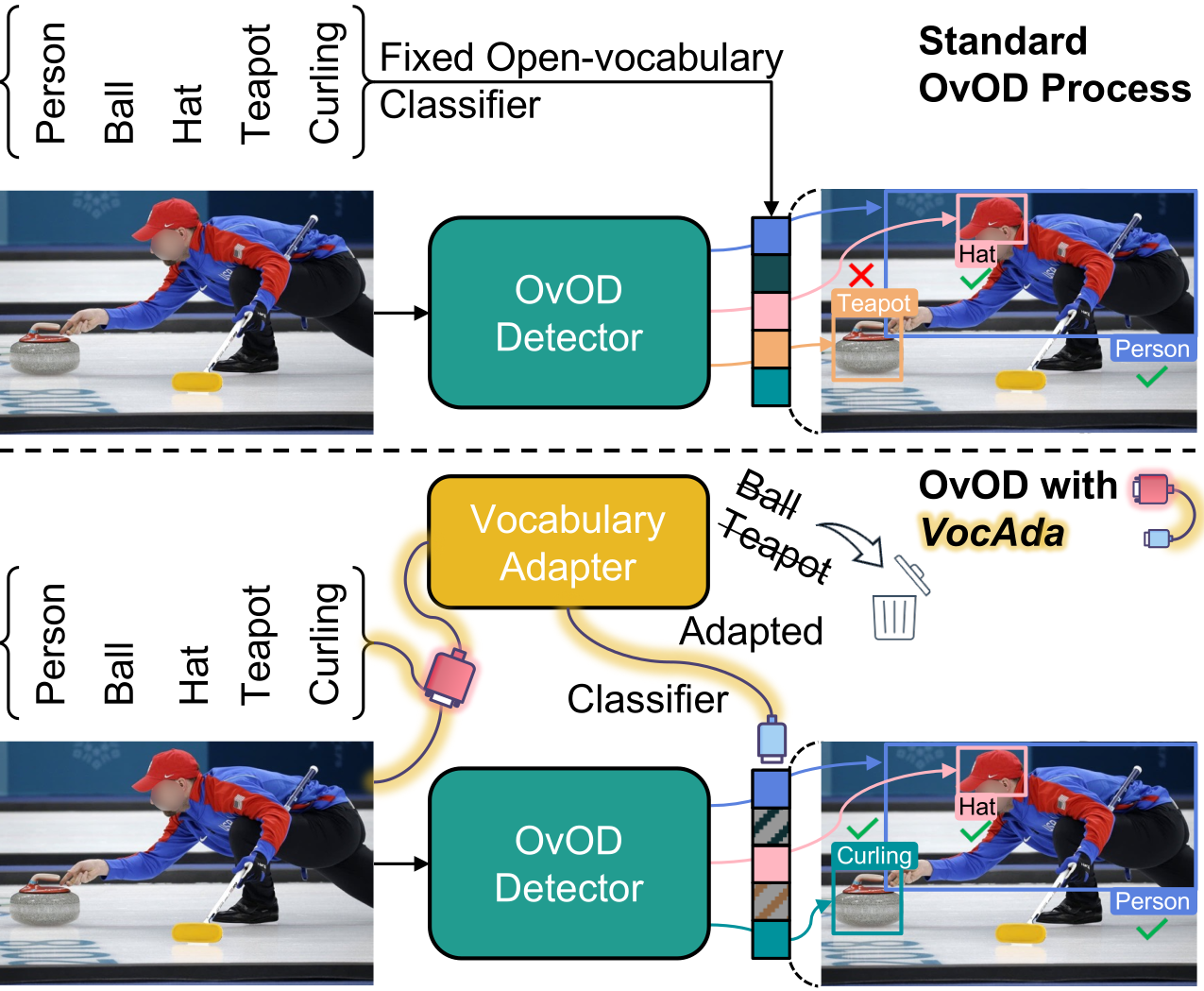
Open-vocabulary object detection models allow users to freely specify a class vocabulary in natural language at test time, guiding the detection of desired objects. However, vocabularies can be overly broad or even mis-specified, hampering the overall performance of the detector. In this work, we propose a plug-and-play Vocabulary Adapter (VocAda) to refine the user-defined vocabulary, automatically tailoring it to categories that are relevant for a given image. VocAda does not require any training, it operates at inference time in three steps: i) it uses an image captionner to describe visible objects, ii) it parses nouns from those captions, and iii) it selects relevant classes from the user-defined vocabulary, discarding irrelevant ones. Experiments on COCO and Objects365 with three state-of-the-art detectors show that VocAda consistently improves performance, proving its versatility.
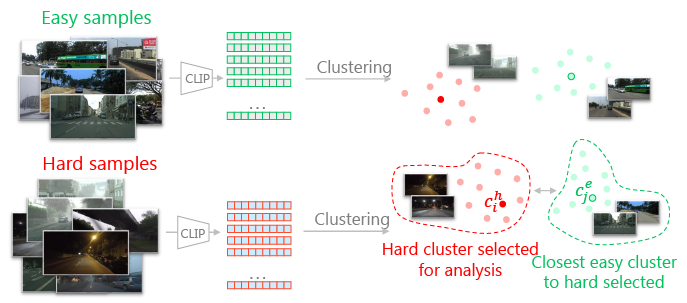
Deep learning models are effective, yet brittle. Even carefully trained, their behavior tends to be hard to predict when confronted with out-of-distribution samples. In this work, our goal is to propose a simple yet effective solution to predict and describe via natural language potential failure modes of computer vision models. Given a pretrained model and a set of samples, our aim is to find sentences that accurately describe the visual conditions in which the model underperforms. In order to study this important topic and foster future research on it, we formalize the problem of Language-Based Error Explainability (LBEE) and propose a set of metrics to evaluate and compare different methods for this task. We propose solutions that operate in a joint vision-and-language embedding space, and can characterize through language descriptions model failures caused, e.g., by objects unseen during training or adverse visual conditions. We experiment with different tasks, such as classification under the presence of dataset bias and semantic segmentation in unseen environments, and show that the proposed methodology isolates nontrivial sentences associated with specific error causes. We hope our work will help practitioners better understand the behavior of models, increasing their overall safety and interpretability.
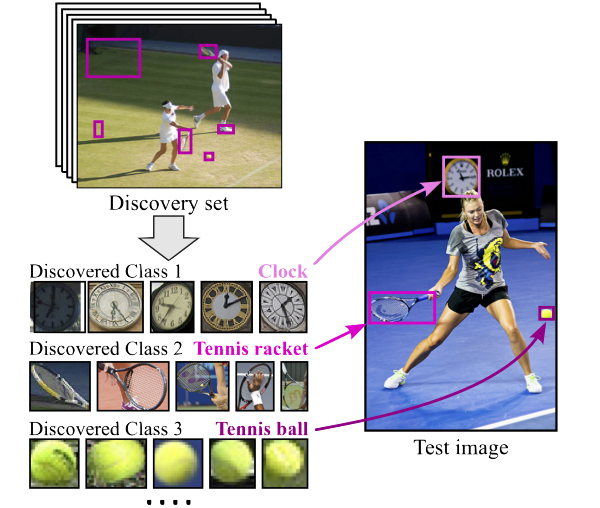
Object detectors are typically trained once and for all on a fixed set of classes. However, this closed-world assumption is unrealistic in practice, as new classes will inevitably emerge after the detector is deployed in the wild. In this work, we look at ways to extend a detector trained for a set of base classes so it can i) spot the presence of novel classes, and ii) automatically enrich its repertoire to be able to detect those newly discovered classes together with the base ones. We propose PANDAS, a method for novel class discovery and detection. It discovers clusters representing novel classes from unlabeled data, and represents old and new classes with prototypes. During inference, a distance-based classifier uses these prototypes to assign a label to each detected object instance. The simplicity of our method makes it widely applicable. We experimentally demonstrate the effectiveness of PANDAS on the VOC 2012 and COCO-to-LVIS benchmarks. It performs favorably against the state of the art for this task while being computationally more affordable.
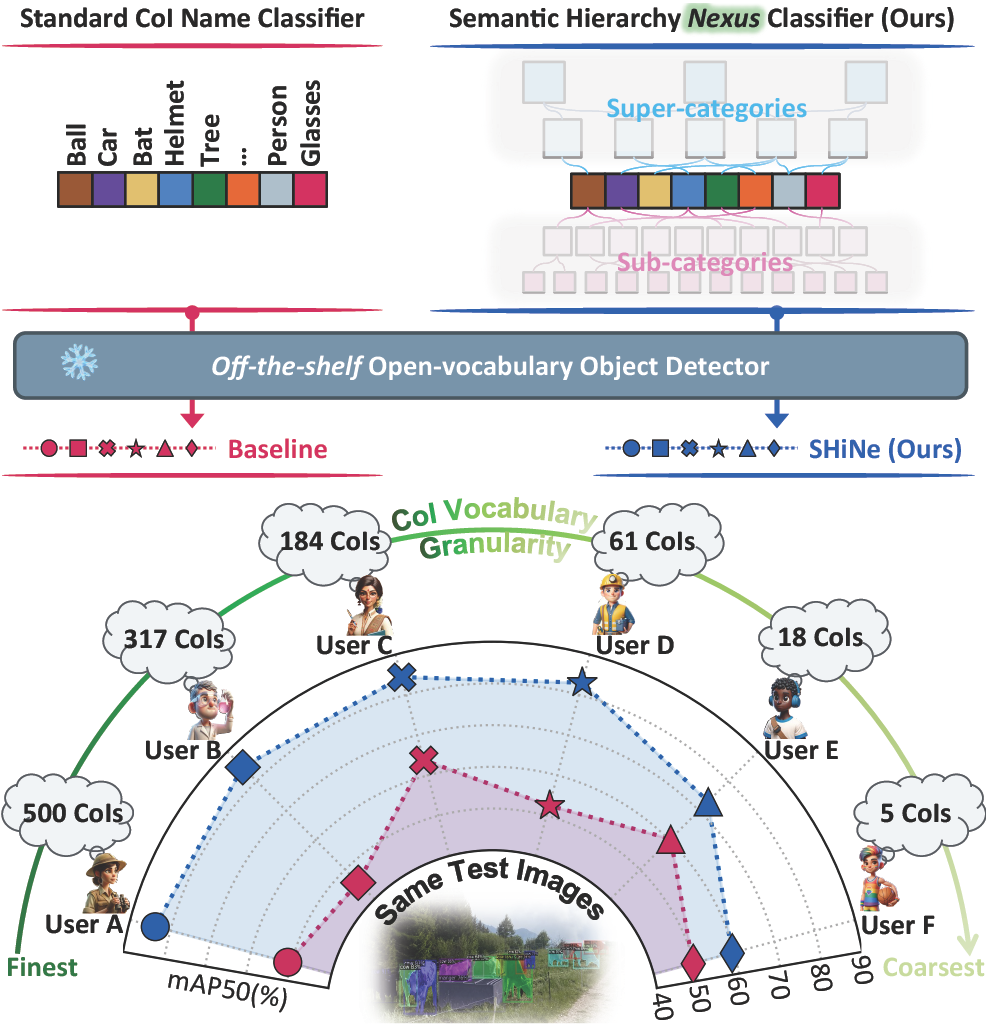
Open-vocabulary object detection (OvOD) has transformed detection into a language-guided task, empowering users to freely define their class vocabularies of interest during inference. However, our initial investigation indicates that existing OvOD detectors exhibit significant variability when dealing with vocabularies across various semantic granularities, posing a concern for real-world deployment. To this end, we introduce Semantic Hierarchy Nexus (SHiNe), a novel classifier that uses semantic knowledge from class hierarchies. It runs offline in three steps: i) it retrieves relevant super-/sub-categories from a hierarchy for each target class; ii) it integrates these categories into hierarchy-aware sentences; iii) it fuses these sentence embeddings to generate the nexus classifier vector. Our evaluation on various detection benchmarks demonstrates that SHiNe enhances robustness across diverse vocabulary granularities, achieving up to +31.9% mAP50 with ground truth hierarchies, while retaining improvements using hierarchies generated by large language models. Moreover, when applied to open-vocabulary classification on ImageNet-1k, SHiNe improves the CLIP zero-shot baseline by +2.8% accuracy. SHiNe is training-free and can be seamlessly integrated with any off-the-shelf OvOD detector, without incurring additional computational overhead during inference
Continual learning is a sub-field of machine learning, which aims to allow machine learning models to continuously learn on new data, by accumulating knowledge without forgetting what was learned in the past. In this work, we take a step back, and ask: "Why should one care about continual learning in the first place?". We set the stage by surveying recent continual learning papers published at three major machine learning conferences, and show that memory-constrained settings dominate the field. Then, we discuss five open problems in machine learning, and even though they seem unrelated to continual learning at first sight, we show that continual learning will inevitably be part of their solution. These problems are model-editing, personalization, on-device learning, faster (re-)training and reinforcement learning. Finally, by comparing the desiderata from these unsolved problems and the current assumptions in continual learning, we highlight and discuss four future directions for continual learning research. We hope that this work offers an interesting perspective on the future of continual learning, while displaying its potential value and the paths we have to pursue in order to make it successful. This work is the result of the many discussions the authors had at the Dagstuhl seminar on Deep Continual Learning, in March 2023.
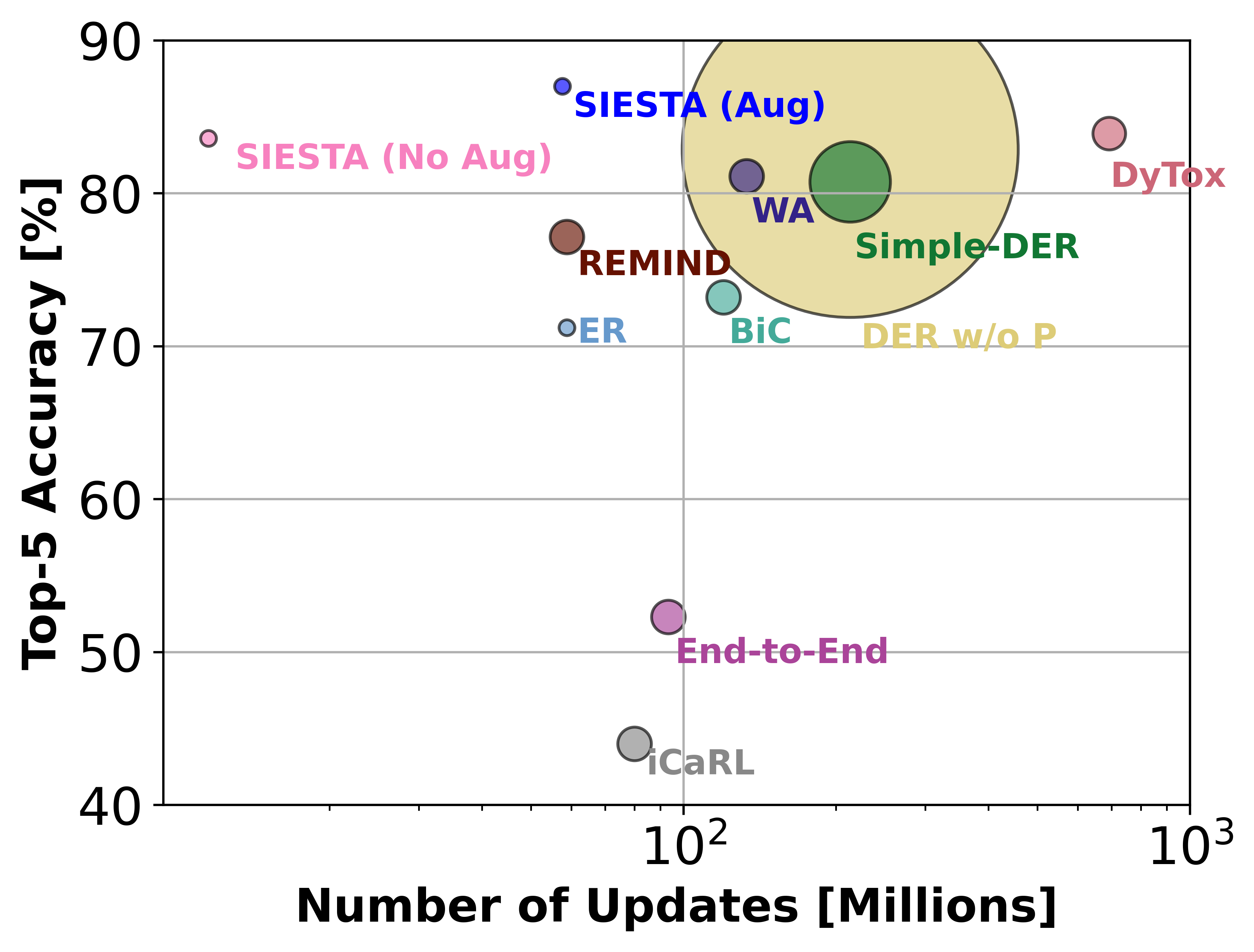
In supervised continual learning, a deep neural network (DNN) is updated with an ever-growing data stream. Unlike the offline setting where data is shuffled, we cannot make any distributional assumptions about the data stream. Ideally, only one pass through the dataset is needed for computational efficiency. However, existing methods are inadequate and make many assumptions that cannot be made for real-world applications, while simultaneously failing to improve computational efficiency. In this paper, we propose a novel online continual learning method, SIESTA based on wake/sleep framework for training, which is well aligned to the needs of on-device learning. The major goal of SIESTA is to advance compute efficient continual learning so that DNNs can be updated efficiently using far less time and energy. The principal innovations of SIESTA are: 1) rapid online updates using a rehearsal-free, backpropagation-free, and data-driven network update rule during its wake phase, and 2) expedited memory consolidation using a compute-restricted rehearsal policy during its sleep phase. For memory efficiency, SIESTA adapts latent rehearsal using memory indexing from REMIND. Compared to REMIND and prior arts, SIESTA is far more computationally efficient, enabling continual learning on ImageNet-1K in under 2.4 hours on a single GPU; moreover, in the augmentation-free setting it matches the performance of the offline learner, a milestone critical to driving adoption of continual learning in real-world applications.

There has been significant progress in creating machine learning models that identify objects in scenes along with their associated attributes and relationships; however, there is a large gap between the best models and human capabilities. One of the major reasons for this gap is the difficulty in collecting sufficient amounts of annotated relations and attributes for training these systems. While some attributes and relations are abundant, the distribution in the natural world and existing datasets is long tailed. In this paper, we address this problem by introducing a novel incremental active learning framework that asks for attributes and relations in visual scenes. While conventional active learning methods ask for labels of specific examples, we flip this framing to allow agents to ask for examples from specific categories. Using this framing, we introduce an active sampling method that asks for examples from the tail of the data distribution and show that it outperforms classical active learning methods on Visual Genome.
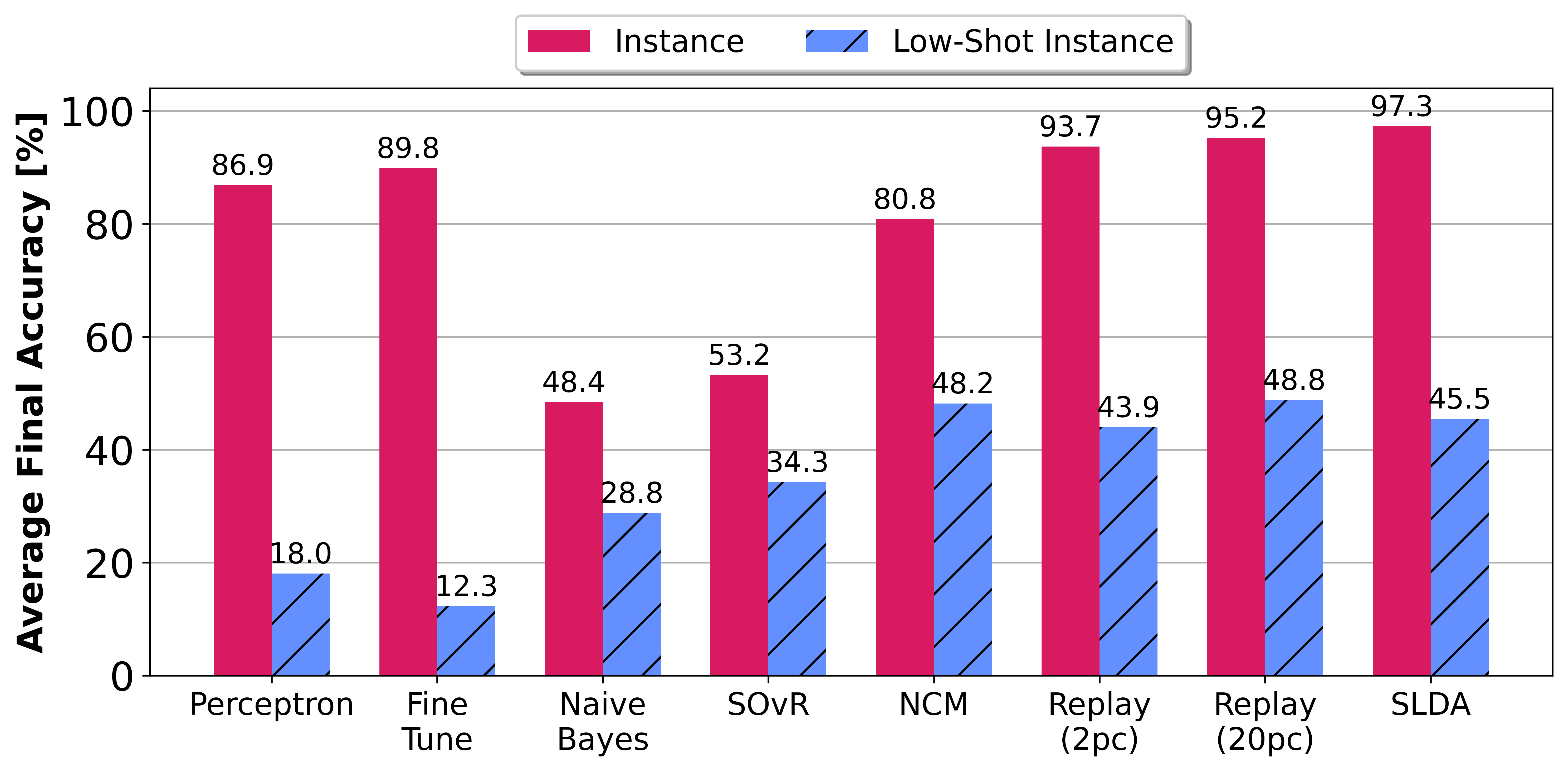
Real-time on-device continual learning is needed for new applications such as home robots, user personalization on smartphones, and augmented/virtual reality headsets. However, this setting poses unique challenges: embedded devices have limited memory and compute capacity and conventional machine learning models suffer from catastrophic forgetting when updated on non-stationary data streams. While several online continual learning models have been developed, their effectiveness for embedded applications has not been rigorously studied. In this paper, we first identify criteria that online continual learners must meet to effectively perform real-time, on-device learning. We then study the efficacy of several online continual learning methods when used with mobile neural networks. We measure their performance, memory usage, compute requirements, and ability to generalize to out-of-domain inputs.
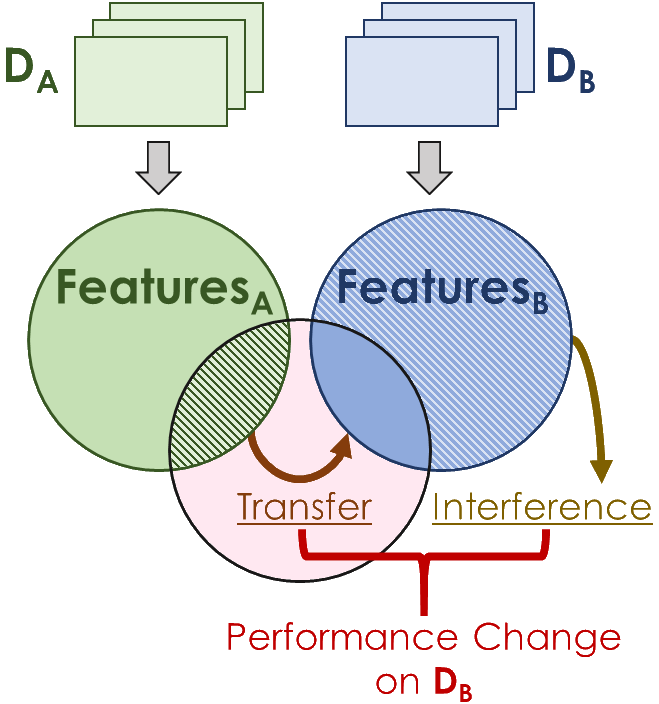
Humans are incredibly good at transferring knowledge from one domain to another, enabling rapid learning of new tasks. Likewise, transfer learning has enabled enormous success in many computer vision problems using pretraining. However, the benefits of transfer in multi-domain learning, where a network learns multiple tasks defined by different datasets, has not been adequately studied. Learning multiple domains could be beneficial or these domains could interfere with each other given limited network capacity. In this work, we decipher the conditions where interference and knowledge transfer occur in multi-domain learning. We propose new metrics disentangling interference and transfer and set up experimental protocols. We further examine the roles of network capacity, task grouping, and dynamic loss weighting in reducing interference and facilitating transfer. We demonstrate our findings on the CIFAR-100, MiniPlaces, and Tiny-ImageNet datasets.
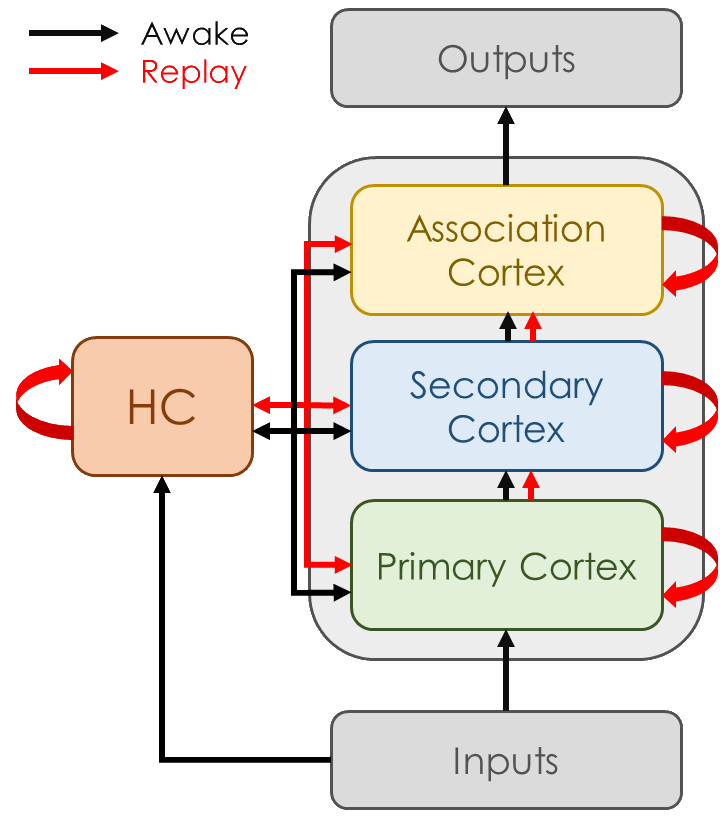
Replay is the reactivation of one or more neural patterns, which are similar to the activation patterns experienced during past waking experiences. Replay was first observed in biological neural networks during sleep, and it is now thought to play a critical role in memory formation, retrieval, and consolidation. Replay-like mechanisms have been incorporated into deep artificial neural networks that learn over time to avoid catastrophic forgetting of previous knowledge. Replay algorithms have been successfully used in a wide range of deep learning methods within supervised, unsupervised, and reinforcement learning paradigms. In this paper, we provide the first comprehensive comparison between replay in the mammalian brain and replay in artificial neural networks. We identify multiple aspects of biological replay that are missing in deep learning systems and hypothesize how they could be utilized to improve artificial neural networks.
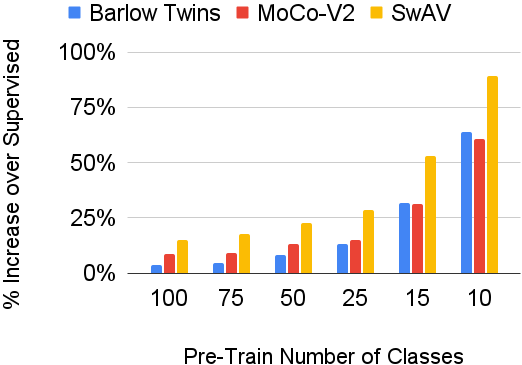
In continual learning, a system must incrementally learn from a non-stationary data stream without catastrophic forgetting. Recently, multiple methods have been devised for incrementally learning classes on large-scale image classification tasks, such as ImageNet. State-of-the-art continual learning methods use an initial supervised pre-training phase, in which the first 10% - 50% of the classes in a dataset are used to learn representations in an offline manner before continual learning of new classes begins. We hypothesize that self-supervised pre-training could yield features that generalize better than supervised learning, especially when the number of samples used for pre-training is small. We test this hypothesis using the self-supervised MoCo-V2 and SwAV algorithms. On ImageNet, we find that both outperform supervised pre-training considerably for online continual learning, and the gains are larger when fewer samples are available. Our findings are consistent across three continual learning algorithms. Our best system achieves a 14.95% relative increase in top-1 accuracy on class incremental ImageNet over the prior state of the art for online continual learning.
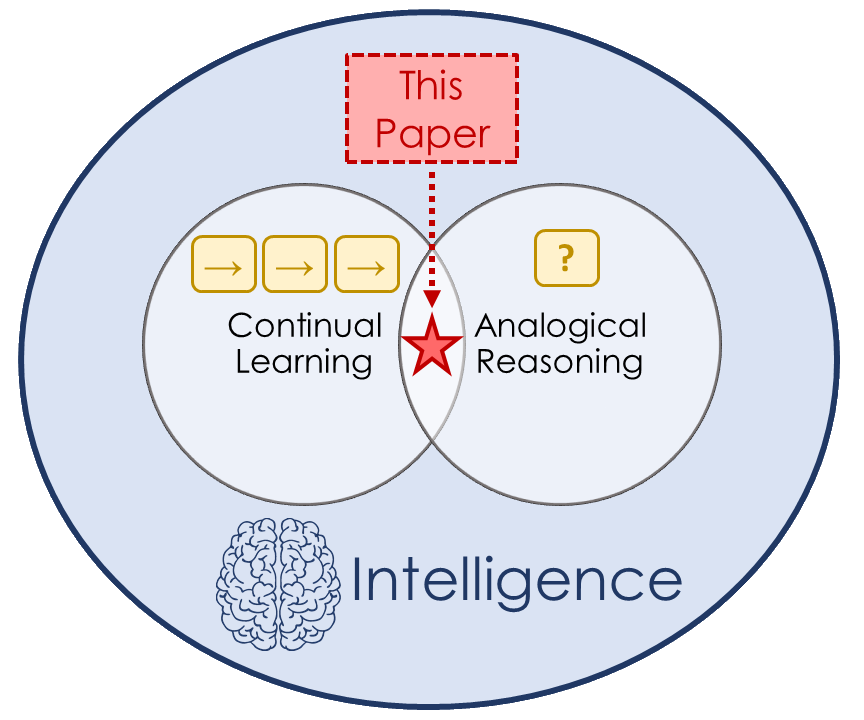
In continual learning, a system learns from non-stationary data streams or batches without catastrophic forgetting. While this problem has been heavily studied in supervised image classification and reinforcement learning, continual learning in neural networks designed for abstract reasoning has not yet been studied. Here, we study continual learning of analogical reasoning. Analogical reasoning tests such as Raven's Progressive Matrices (RPMs) are commonly used to measure non-verbal abstract reasoning in humans, and recently offline neural networks for the RPM problem have been proposed. In this paper, we establish experimental baselines, protocols, and forward and backward transfer metrics to evaluate continual learners on RPMs. We employ experience replay to mitigate catastrophic forgetting. Prior work using replay for image classification tasks has found that selectively choosing the samples to replay offers little, if any, benefit over random selection. In contrast, we find that selective replay can significantly outperform random selection for the RPM task.
Supervised classification methods often assume the train and test data distributions are the same and that all classes in the test set are present in the training set. However, deployed classifiers often require the ability to recognize inputs from outside the training set as unknowns. This problem has been studied under multiple paradigms including out-of-distribution detection and open set recognition. For convolutional neural networks, there have been two major approaches: 1) inference methods to separate knowns from unknowns and 2) feature space regularization strategies to improve model robustness to novel inputs. Up to this point, there has been little attention to exploring the relationship between the two approaches and directly comparing performance on large-scale datasets that have more than a few dozen categories. Using the ImageNet ILSVRC-2012 large-scale classification dataset, we identify novel combinations of regularization and specialized inference methods that perform best across multiple open set classification problems of increasing difficulty level. We find that input perturbation and temperature scaling yield significantly better performance on large-scale datasets than other inference methods tested, regardless of the feature space regularization strategy. Conversely, we find that improving performance with advanced regularization schemes during training yields better performance when baseline inference techniques are used; however, when advanced inference methods are used to detect open set classes, the utility of these combersome training paradigms is less evident.
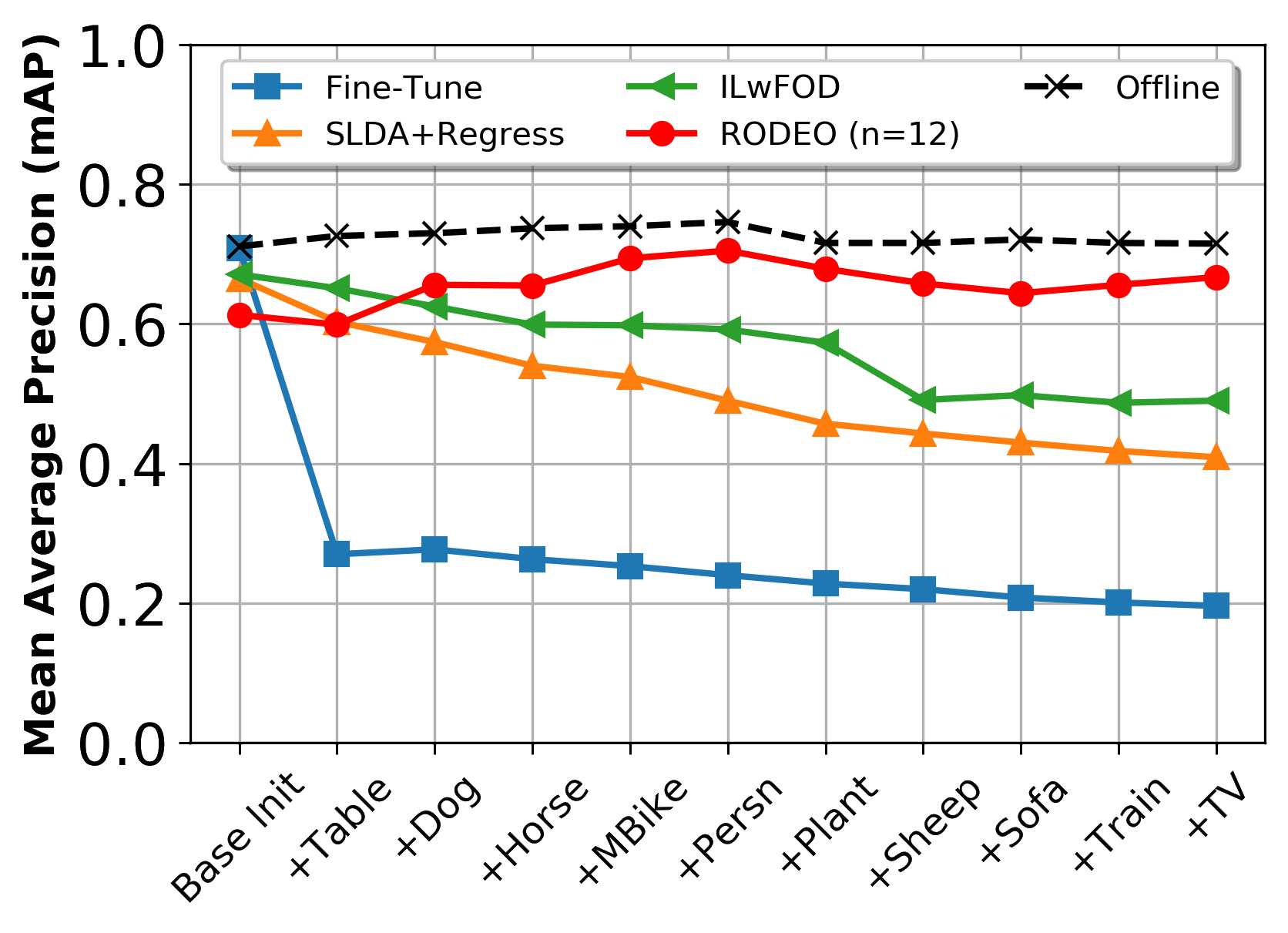
Humans can incrementally learn to do new visual detection tasks, which is a huge challenge for today's computer vision systems. Incrementally trained deep learning models lack backwards transfer to previously seen classes and suffer from a phenomenon known as catastrophic forgetting. In this paper, we pioneer online streaming learning for object detection, where an agent must learn examples one at a time with severe memory and computational constraints. In object detection, a system must output all bounding boxes for an image with the correct label. Unlike earlier work, the system described in this paper can learn how to do this task in an online manner with new classes being introduced over time. We achieve this capability by using a novel memory replay mechanism that replays entire scenes in an efficient manner. We achieve state-of-the-art results on both the PASCAL VOC 2007 and MS COCO datasets.
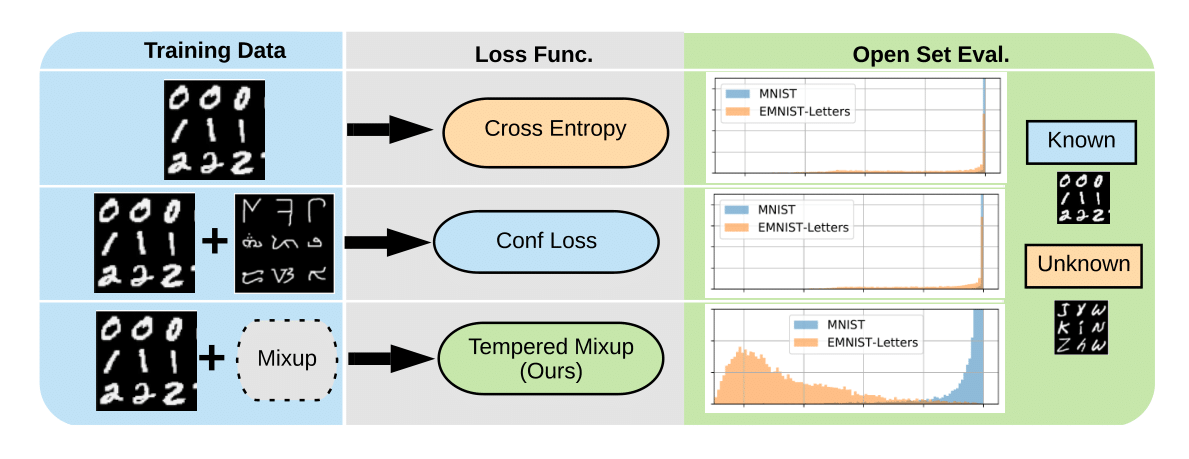
Supervised classification methods often assume that evaluation data is drawn from the same distribution as training data and that all classes are present for training. However, real-world classifiers must handle inputs that are far from the training distribution including samples from unknown classes. Open set robustness refers to the ability to properly label samples from previously unseen categories as novel and avoid high-confidence, incorrect predictions. Existing approaches have focused on either novel inference methods, unique training architectures, or supplementing the training data with additional background samples. Here, we propose a simple regularization technique easily applied to existing CNN architectures that improves open set robustness without a background dataset. Our method achieves state-of-the-art results on open set classification baselines and easily scales to large-scale open set classification problems.
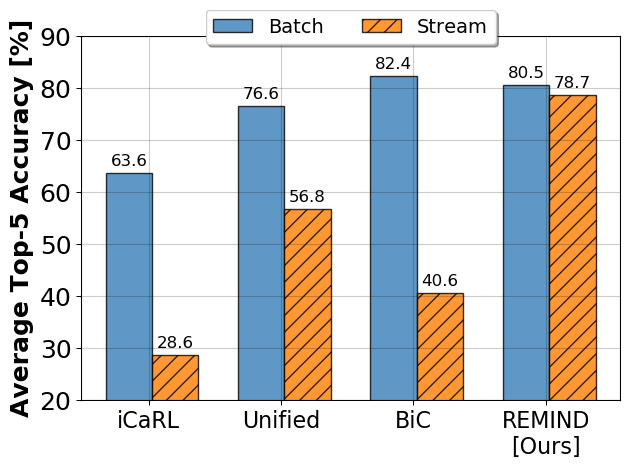
People learn throughout life. However, incrementally updating conventional neural networks leads to catastrophic forgetting. A common remedy is replay, which is inspired by how the brain consolidates memory. Replay involves fine-tuning a network on a mixture of new and old instances. While there is neuroscientific evidence that the brain replays compressed memories, existing methods for convolutional networks replay raw images. Here, we propose REMIND, a brain-inspired approach that enables efficient replay with compressed representations. REMIND is trained in an online manner, meaning it learns one example at a time, which is closer to how humans learn. Under the same constraints, REMIND outperforms other methods for incremental class learning on the ImageNet ILSVRC-2012 dataset. We probe REMIND's robustness to data ordering schemes known to induce catastrophic forgetting. We demonstrate REMIND's generality by pioneering online learning for Visual Question Answering (VQA).
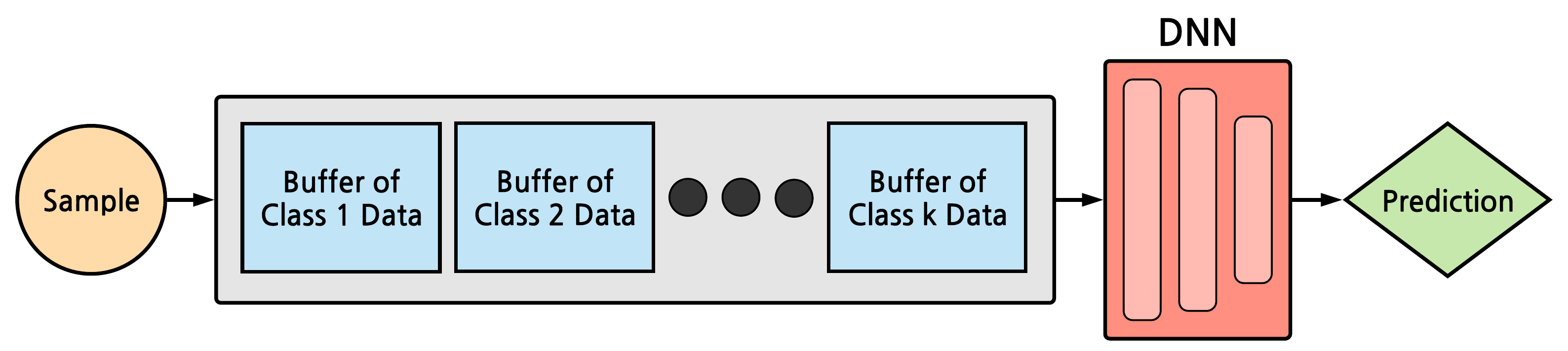
When an agent acquires new information, ideally it would immediately be capable of using that information to understand its environment. This is not possible using conventional deep neural networks, which suffer from catastrophic forgetting when they are incrementally updated, with new knowledge overwriting established representations. A variety of approaches have been developed that attempt to mitigate catastrophic forgetting in the incremental batch learning scenario, where a model learns from a series of large collections of labeled samples. However, in this setting, inference is only possible after a batch has been accumulated, which prohibits many applications. An alternative paradigm is online learning in a single pass through the training dataset on a resource constrained budget, which is known as streaming learning. Streaming learning has been much less studied in the deep learning community. In streaming learning, an agent learns instances one-by-one and can be tested at any time, rather than only after learning a large batch. Here, we revisit streaming linear discriminant analysis, which has been widely used in the data mining research community. By combining streaming linear discriminant analysis with deep learning, we are able to outperform both incremental batch learning and streaming learning algorithms on both ImageNet ILSVRC-2012 and CORe50, a dataset that involves learning to classify from temporally ordered samples.
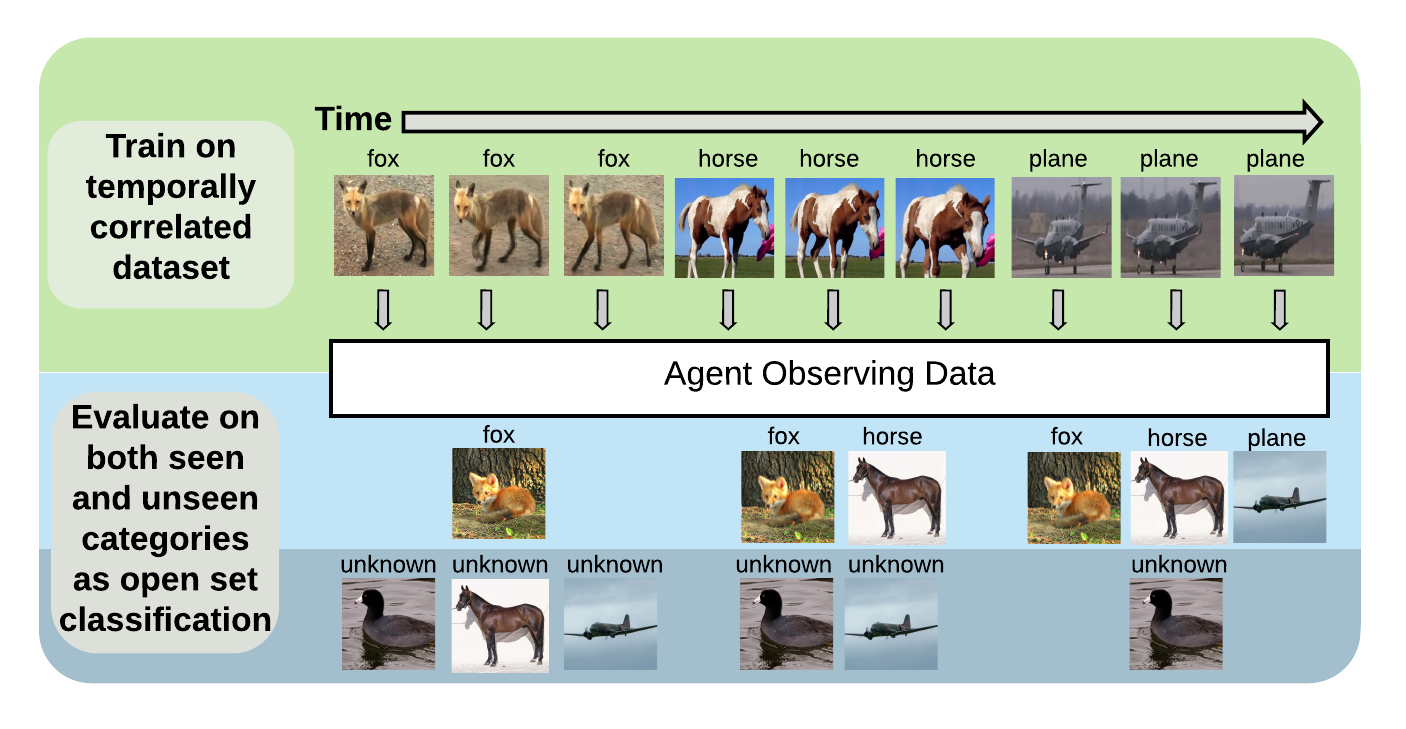
Deep neural networks are popular for visual perception tasks such as image classification and object detection. Once trained and deployed in a real-time environment, these models struggle to identify novel inputs not initially represented in the training distribution. Further, they cannot be easily updated on new information or they will catastrophically forget previously learned knowledge. While there has been much interest in developing models capable of overcoming forgetting, most research has focused on incrementally learning from common image classification datasets broken up into large batches. Online streaming learning is a more realistic paradigm where a model must learn one sample at a time from temporally correlated data streams. Although there are a few datasets designed specifically for this protocol, most have limitations such as few classes or poor image quality. In this work, we introduce Stream-51, a new dataset for streaming classification consisting of temporally correlated images from 51 distinct object categories and additional evaluation classes outside of the training distribution to test novelty recognition. We establish unique evaluation protocols, experimental metrics, and baselines for our dataset in the streaming paradigm.
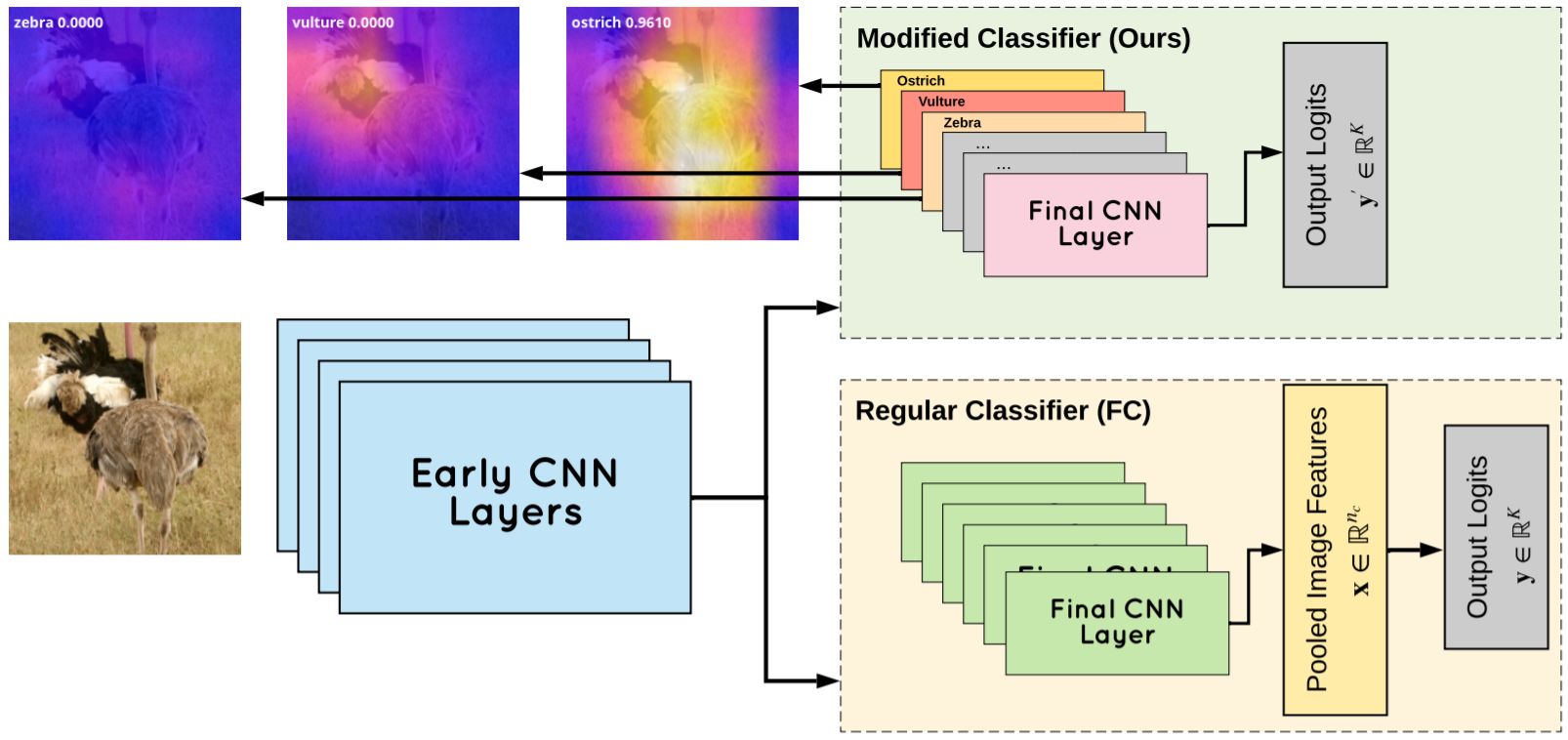
Traditionally, deep convolutional neural networks consist of a series of convolutional and pooling layers followed by one or more fully connected (FC) layers to perform the final classification. While this design has been successful, for datasets with a large number of categories, the fully connected layers often account for a large percentage of the network's parameters. For applications with memory constraints, such as mobile devices and embedded platforms, this is not ideal. Recently, a family of architectures that involve replacing the learned fully connected output layer with a fixed layer has been proposed as a way to achieve better efficiency. In this paper we examine this idea further and demonstrate that fixed classifiers offer no additional benefit compared to simply removing the output layer along with its parameters. We further demonstrate that the typical approach of having a fully connected final output layer is inefficient in terms of parameter count. We are able to achieve comparable performance to a traditionally learned fully connected classification output layer on the ImageNet-1K, CIFAR-100, Stanford Cars-196, and Oxford Flowers-102 datasets, while not having a fully connected output layer at all.
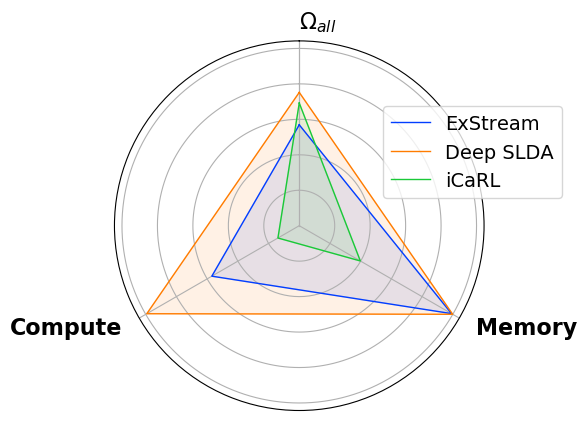
In supervised machine learning, an agent is typically trained once and then deployed. While this works well for static settings, robots often operate in changing environments and must quickly learn new things from data streams. In this paradigm, known as streaming learning, a learner is trained online, in a single pass, from a data stream that cannot be assumed to be independent and identically distributed (iid). Streaming learning will cause conventional deep neural networks (DNNs) to fail for two reasons: 1) they need multiple passes through the entire dataset; and 2) non-iid data will cause catastrophic forgetting. An old fix to both of these issues is rehearsal. To learn a new example, rehearsal mixes it with previous examples, and then this mixture is used to update the DNN. Full rehearsal is slow and memory intensive because it stores all previously observed examples, and its effectiveness for preventing catastrophic forgetting has not been studied in modern DNNs. Here, we describe the ExStream algorithm for memory efficient rehearsal and compare it to alternatives. We find that full rehearsal can eliminate catastrophic forgetting in a variety of streaming learning settings, with ExStream performing well using far less memory and computation.
In order for a robotic agent to learn successfully in an uncontrolled environment, it must be able to immediately alter its behavior. Deep neural networks are the dominant approach for classification tasks in computer vision, but typical algorithms and architectures are incapable of immediately learning new tasks without catastrophically forgetting previously acquired knowledge. There has been renewed interest in solving this problem, but there are limitations to existing solutions, including poor performance compared to offline models, large memory footprints, and learning slowly. In this abstract, we formalize the continual learning paradigm and propose new benchmarks for assessing continual learning agents.
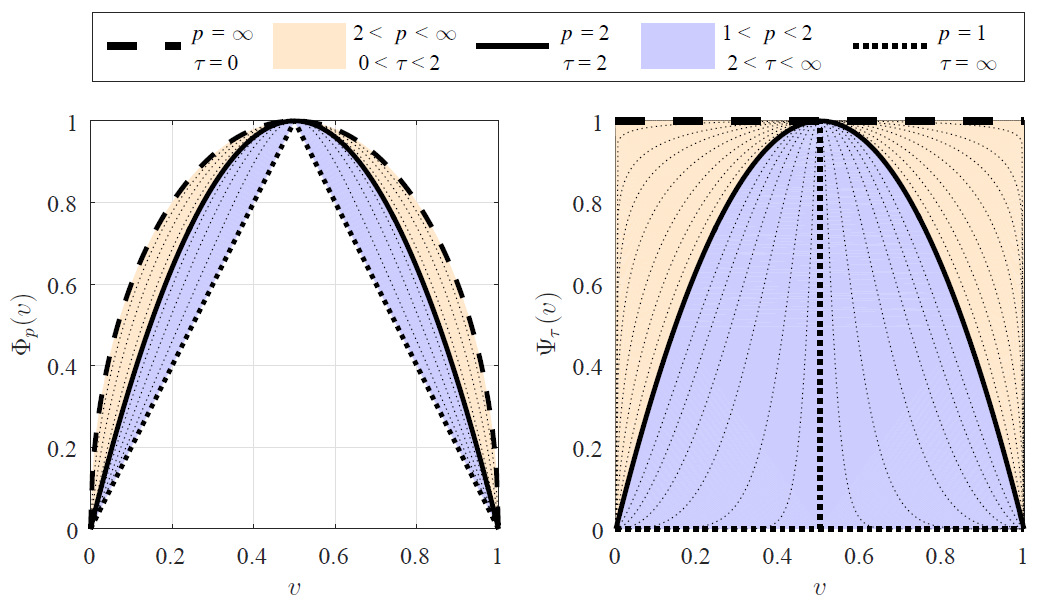
The Normalized Cut (NCut) objective function, widely used in data clustering and image segmentation, quantifies the cost of graph partitioning in a way that biases clusters or segments that are balanced towards having lower values than unbalanced partitionings. However, this bias is so strong that it avoids any singleton partitions, even when vertices are very weakly connected to the rest of the graph. Motivated by the Buhler-Hein family of balanced cut costs, we propose the family of Compassionately Conservative Balanced (CCB) Cut costs, which are indexed by a parameter that can be used to strike a compromise between the desire to avoid too many singleton partitions and the notion that all partitions should be balanced. We show that CCB-Cut minimization can be relaxed into an orthogonally constrained lτ -minimization problem that coincides with the problem of computing Piecewise Flat Embeddings (PFE) for one particular index value, and we present an algorithm for solving the relaxed problem by iteratively minimizing a sequence of reweighted Rayleigh quotients (IRRQ). Using images from the BSDS500 database, we show that image segmentation based on CCB-Cut minimization provides better accuracy with respect to ground truth and greater variability in region size than NCut-based image segmentation.
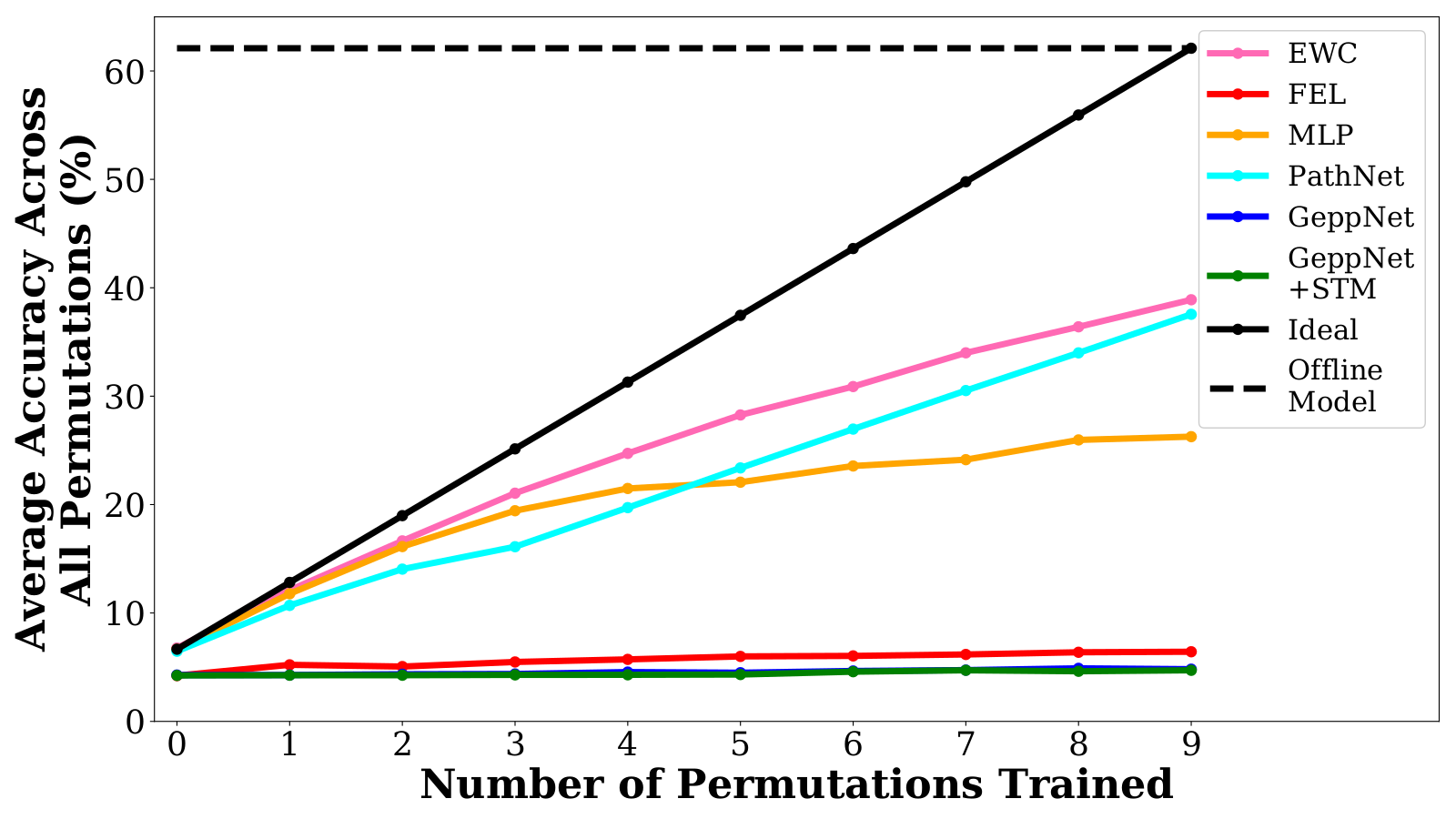
Deep neural networks are used in many state-of-the-art systems for machine perception. Once a network is trained to do a specific task, e.g., bird classification, it cannot easily be trained to do new tasks, e.g., incrementally learning to recognize additional bird species or learning an entirely different task such as flower recognition. When new tasks are added, typical deep neural networks are prone to catastrophically forgetting previous tasks. Networks that are capable of assimilating new information incrementally, much like how humans form new memories over time, will be more efficient than retraining the model from scratch each time a new task needs to be learned. There have been multiple attempts to develop schemes that mitigate catastrophic forgetting, but these methods have not been directly compared, the tests used to evaluate them vary considerably, and these methods have only been evaluated on small-scale problems (e.g., MNIST). In this paper, we introduce new metrics and benchmarks for directly comparing five different mechanisms designed to mitigate catastrophic forgetting in neural networks: regularization, ensembling, rehearsal, dual-memory, and sparse-coding. Our experiments on real-world images and sounds show that the mechanism(s) that are critical for optimal performance vary based on the incremental training paradigm and type of data being used, but they all demonstrate that the catastrophic forgetting problem has yet to be solved.